


词频统计代码
// 用于统计文本文件中每个单词出现的次数
package WC;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.util.StringTokenizer;
public class WordCount {
// 定义Mapper类
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
// 一个IntWritable实例,表示计数1
private final static IntWritable one = new IntWritable(1);
// 用于存储当前处理的单词
private Text word = new Text();
// map方法:将输入的一行文本拆分成单词,并为每个单词生成一个键值对
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 使用空格作为分隔符将输入行拆分为单词
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
// 设置当前单词
word.set(itr.nextToken());
// 输出键值对 (单词, 1)
context.write(word, one);
}
}
}
// 定义Reducer类
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 用于存储单词的总出现次数
private IntWritable result = new IntWritable();
// reduce方法:汇总相同单词的所有计数值
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
// 累加所有相同的单词的计数值
sum += val.get();
}
// 设置结果计数值
result.set(sum);
// 输出最终的键值对 (单词, 总计数)
context.write(key, result);
}
}
// 主方法
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 解析命令行参数,获取Hadoop通用选项(如输入输出路径)
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
// 检查是否提供了足够的参数
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
// 创建Job实例
Job job = Job.getInstance(conf, "word count");
// 设置主类
job.setJarByClass(WordCount.class);
// 设置Mapper类
job.setMapperClass(TokenizerMapper.class);
// 可选:设置Combiner类(这里被注释掉了)
// job.setCombinerClass(IntSumReducer.class);
// 设置Reducer类
job.setReducerClass(IntSumReducer.class);
// 设置输出键的类型
job.setOutputKeyClass(Text.class);
// 设置输出值的类型
job.setOutputValueClass(IntWritable.class);
// 添加输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
// 提交作业并等待完成
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
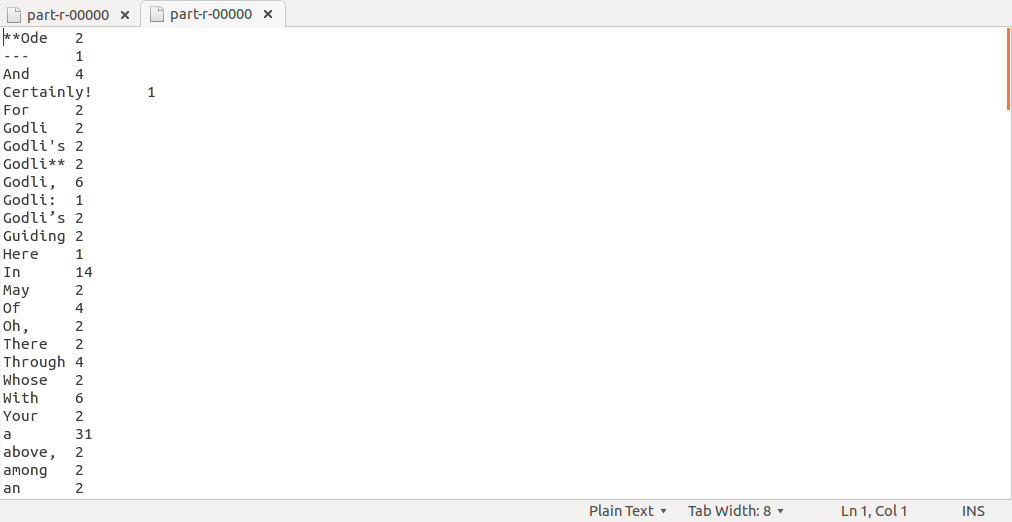
倒排索引代码
// 统计每个单词在哪些文件中出现以及具体的行偏移量。
package II;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; // 使用 mapreduce API 中的 FileSplit
import java.util.StringTokenizer;
public class Inverted {
// 定义Mapper类
public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, Text> {
// map方法:将输入的一行文本拆分成单词,并为每个单词生成一个键值对
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 获取当前处理的文件分片
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName(); // 获取文件名
long offset = key.get(); // 获取行偏移量
// 使用空格作为分隔符将输入行拆分为单词
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
String word = itr.nextToken(); // 获取当前单词
// 将文件名和行偏移量组合成一个字符串
String fileName_offset = fileName + ":" + offset;
// 输出键值对 (单词, 文件名:行偏移量)
context.write(new Text(word), new Text(fileName_offset));
}
}
}
// 定义Reducer类
public static class IndexReducer extends Reducer<Text, Text, Text, Text> {
private Text result = new Text();
// reduce方法:汇总相同单词的所有文件名和行偏移量
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder nameList = new StringBuilder();
for (Text val : values) {
if (nameList.length() > 0) {
nameList.append(";"); // 用分号分隔不同的文件名和行偏移量
}
nameList.append(val.toString()); // 添加当前的文件名和行偏移量
}
result.set(nameList.toString()); // 设置结果字符串
context.write(key, result); // 输出最终的键值对 (单词, 文件名1:行偏移量1;文件名2:行偏移量2;...)
}
}
// 主方法
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 解析命令行参数,获取Hadoop通用选项(如输入输出路径)
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
// 检查是否提供了足够的参数
if (otherArgs.length < 2) {
System.err.println("Usage: inverted index <in> [<in>...] <out>");
System.exit(2);
}
// 创建Job实例
Job job = Job.getInstance(conf, "inverted index");
// 设置主类
job.setJarByClass(Inverted.class);
// 设置Mapper类
job.setMapperClass(TokenizerMapper.class);
// 设置Reducer类
job.setReducerClass(IndexReducer.class);
// 设置输出键的类型
job.setOutputKeyClass(Text.class);
// 设置输出值的类型
job.setOutputValueClass(Text.class);
// 添加多个输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
// 提交作业并等待完成
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}(该功能存在待解决问题,如分词未清洗,同一文章同一单词未去重等)
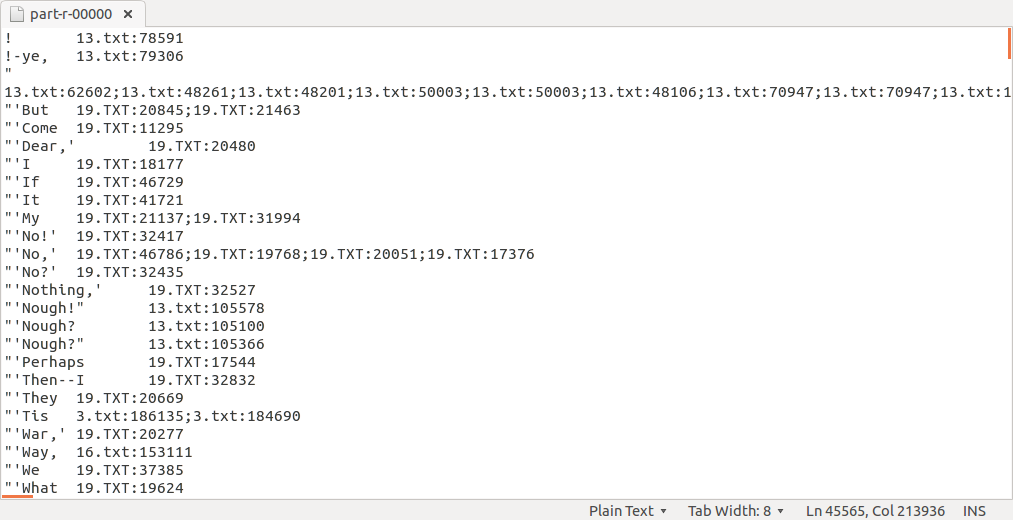
专利引用
package pt;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Patent {
// 定义Mapper类
public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, Text> {
// 用于存储引用专利
private Text Citing = new Text();
// 用于存储被引用专利
private Text Cited = new Text();
// map方法:将输入的一行文本拆分成引用专利和被引用专利,并生成键值对
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 使用逗号作为分隔符将输入行拆分为两个部分
StringTokenizer itr = new StringTokenizer(value.toString(), ",");
while (itr.hasMoreTokens()) {
if (itr.hasMoreTokens()) {
Citing.set(itr.nextToken()); // 获取引用专利
}
if (itr.hasMoreTokens()) {
Cited.set(itr.nextToken()); // 获取被引用专利
}
// 输出键值对 (被引用专利, 引用专利)
context.write(new Text(Cited), new Text(Citing));
}
}
}
// 定义Reducer类
public static class IndexReducer extends Reducer<Text, Text, Text, Text> {
// 用于存储结果字符串
private Text result = new Text();
// reduce方法:汇总相同被引用专利的所有引用专利,并在最后加上引用次数
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder nameList = new StringBuilder();
long num = 0; // 用于计数引用次数
for (Text val : values) {
if (nameList.length() > 0) {
nameList.append(","); // 用逗号分隔不同的引用专利
}
nameList.append(val.toString()); // 添加当前的引用专利
num++; // 增加引用次数
}
// 追加引用次数
nameList.append(" (").append(num).append(")");
result.set(nameList.toString()); // 设置结果字符串
context.write(key, result); // 输出最终的键值对 (被引用专利, 引用专利1,引用专利2,... (引用次数))
}
}
// 主方法
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 解析命令行参数,获取Hadoop通用选项(如输入输出路径)
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
// 检查是否提供了足够的参数
if (otherArgs.length < 2) {
System.err.println("Usage: patent index <in> [<in>...] <out>");
System.exit(2);
}
// 创建Job实例
Job job = Job.getInstance(conf, "Cited Citing");
// 设置主类
job.setJarByClass(Patent.class);
// 设置Mapper类
job.setMapperClass(TokenizerMapper.class);
// 设置Reducer类
job.setReducerClass(IndexReducer.class);
// 设置输出键的类型
job.setOutputKeyClass(Text.class);
// 设置输出值的类型
job.setOutputValueClass(Text.class);
// 添加多个输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
// 提交作业并等待完成
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
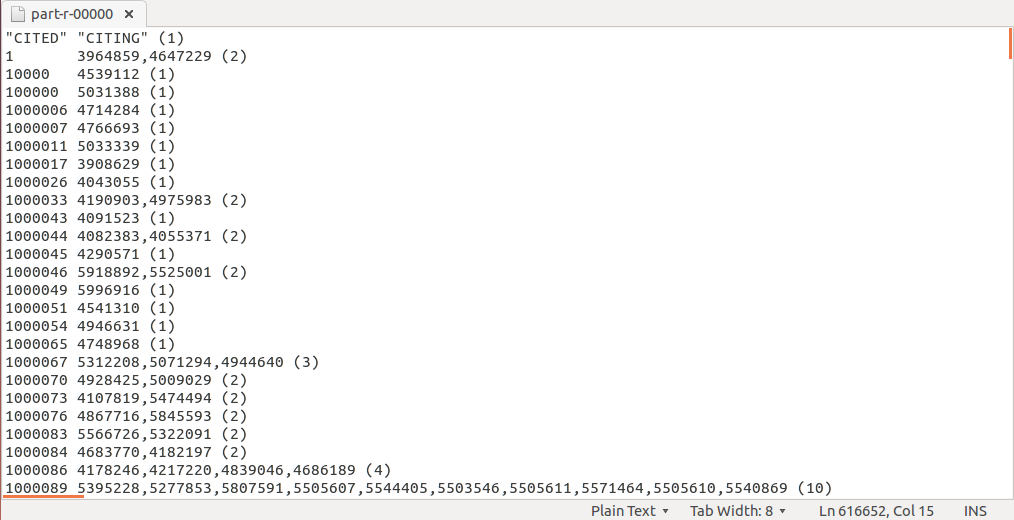
}
专利描述数据集分析
一共有三个代码,分别实现:
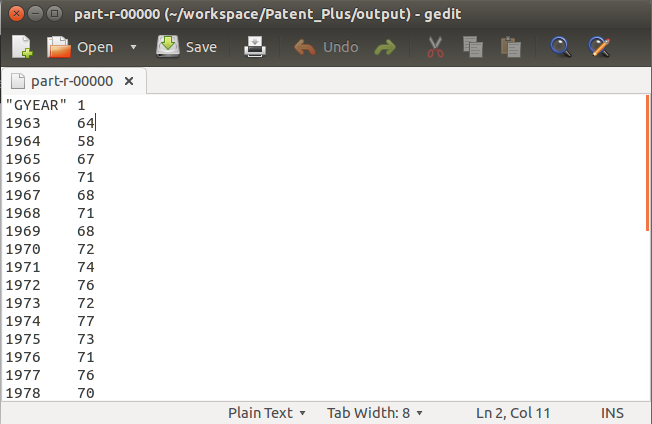
年份专利数统计、国家专利数统计、每年得到美国授权的国家统计
年份专利数统计
package PP;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Patent_Plus {
public static class TokenizerMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text[] Parameters; // 用于存储分割后的各个字段
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 初始化Parameters数组,大小与字段数量相同
Parameters = new Text[23]; // 假设有22个字段
for (int i = 0; i < Parameters.length; i++) {
Parameters[i] = new Text();
}
}
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split(","); // 使用-1参数来确保尾部空字符串也被包含
// 检查是否确实有22个字段
if (fields.length <= 23) {
for (int i = 0; i < fields.length; i++) {
Parameters[i].set(fields[i]);
}
context.write(Parameters[1], new IntWritable(1));
} else {
// 如果不是22个字段,可以选择记录错误或跳过这条记录
System.err.println("Invalid record: " + fields.length);
}
}
}
public static class IndexReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: inverted index <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "Cited Citing");
job.setJarByClass(Patent_Plus.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 添加多个输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

国家专利数统计
package PP;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Patent_Country {
public static class TokenizerMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text[] Parameters; // 用于存储分割后的各个字段
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 初始化Parameters数组,大小与字段数量相同
Parameters = new Text[23]; // 假设有22个字段
for (int i = 0; i < Parameters.length; i++) {
Parameters[i] = new Text();
}
}
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split(","); // 使用-1参数来确保尾部空字符串也被包含
// 检查是否确实有22个字段
if (fields.length <= 23) {
for (int i = 0; i < fields.length; i++) {
Parameters[i].set(fields[i]);
}
// 输出 "Country" 字段和计数器
context.write(Parameters[4], new IntWritable(1));
} else {
// 如果不是22个字段,可以选择记录错误或跳过这条记录
System.err.println("Invalid record: " + fields.length);
}
}
}
public static class IndexReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: inverted index <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "Cited Citing");
job.setJarByClass(Patent_Country.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 添加多个输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
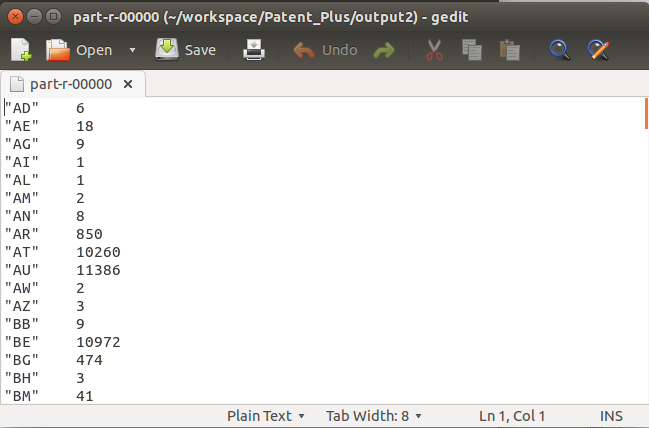
每年得到美国授权的国家统计
package PP;
import java.io.IOException;
import java.util.StringTokenizer;
import java.util.HashSet;
import java.util.Set;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Patent_US {
public static class TokenizerMapper
extends Mapper<LongWritable, Text, Text, Text> {
private Text[] Parameters; // 用于存储分割后的各个字段
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 初始化Parameters数组,大小与字段数量相同
Parameters = new Text[23]; // 假设有22个字段
for (int i = 0; i < Parameters.length; i++) {
Parameters[i] = new Text();
}
}
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split(","); // 使用-1参数来确保尾部空字符串也被包含
// 检查是否确实有22个字段
if (fields.length <= 23) {
for (int i = 0; i < fields.length; i++) {
Parameters[i].set(fields[i]);
}
context.write(Parameters[1], Parameters[4]);
} else {
// 如果不是22个字段,可以选择记录错误或跳过这条记录
System.err.println("Invalid record: " + fields.length);
}
}
}
public static class IndexReducer
extends Reducer<Text, Text, Text, IntWritable> {
private IntWritable count = new IntWritable();
@Override
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
Set<Text> uniqueValues = new HashSet<>(); // 使用HashSet来存储不同的值
for (Text value : values) {
uniqueValues.add(value);
}
// 输出键和对应的不同值的数量
count.set(uniqueValues.size());
context.write(key, count);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: inverted index <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "Cited Citing");
job.setJarByClass(Patent_US.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 添加多个输入路径
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
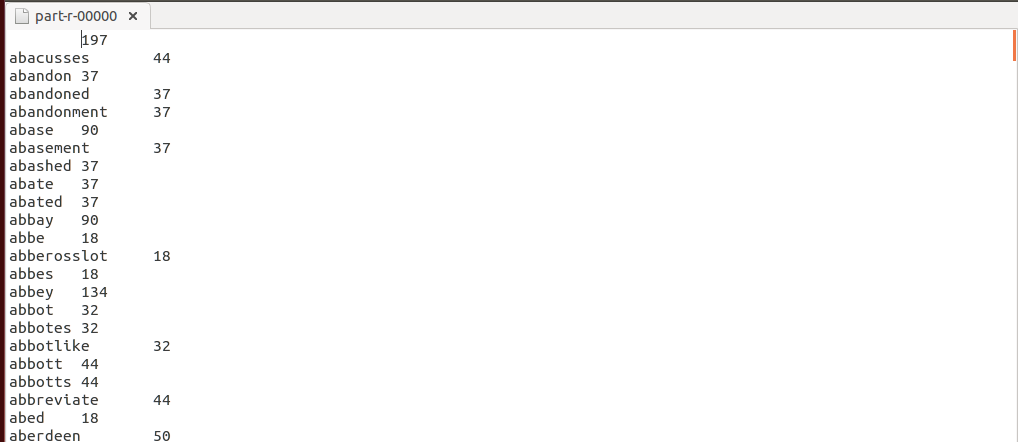
词频统计并去除停用词
分布式缓存分发
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package WP;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.filecache.DistributedCache;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.BufferedReader;
public class WordCount_1 {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
protected List<String> stops = new ArrayList<>();
@Override
protected void setup(Context context)throws IOException,InterruptedException{
//get path road
Path [] paths=DistributedCache.getLocalCacheFiles(context.getConfiguration());
//read the data
BufferedReader sbr = new BufferedReader(new FileReader(paths[0].toUri().getPath()));
String line;
while ((line = sbr.readLine()) != null) {
// 假设每行只有一个停用词
stops.add(line.trim());
}
sbr.close();
}
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
String cleanedWord = word.toString().replaceAll("[^a-zA-Z]", "").toLowerCase();
if(!stops.contains(cleanedWord)) {
word.set(cleanedWord);
context.write(word, one);
}
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
private int k;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 从配置中读取频率阈值
k = context.getConfiguration().getInt("wordcount.frequency.threshold", 10);
}
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
if(sum > k)
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
int frequencyThreshold = 10; // 你可以根据需要更改这个值
conf.setInt("wordcount.frequency.threshold", frequencyThreshold);
Job job = Job.getInstance(conf, "word count(plus)");
job.setJarByClass(WordCount_1.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
job.addCacheFile(new URI("stopwords.txt"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
HDFS共享
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package WP;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
import java.net.URL;
import java.net.URI;
import java.io.InputStream;
import java.io.InputStreamReader;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.filecache.DistributedCache;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.BufferedReader;
public class WordCount_2 {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
protected static List<String> stops = new ArrayList<>();
static{URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());}
@Override
protected void setup(Context context)throws IOException,InterruptedException{
InputStream in = new URL("hdfs://localhost:9000/stop/stopwords.txt").openStream();
BufferedReader sb = new BufferedReader(new InputStreamReader(in));
String line;
while ((line = sb.readLine()) != null) {
// 假设每行只有一个停用词
stops.add(line.trim());
}
sb.close();
}
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
String cleanedWord = word.toString().replaceAll("[^a-zA-Z]", "").toLowerCase();
if(!stops.contains(cleanedWord)) {
word.set(cleanedWord);
context.write(word, one);
}
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
private int k;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 从配置中读取频率阈值
k = context.getConfiguration().getInt("wordcount.frequency.threshold", 10);
}
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
if(sum > k)
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
int frequencyThreshold = 10; // 你可以根据需要更改这个值
conf.setInt("wordcount.frequency.threshold", frequencyThreshold);
Job job = Job.getInstance(conf, "word count(plus)");
job.setJarByClass(WordCount_2.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}最终效果如下:
KNN鸢尾花分类(两种实现方法)
训练集较大情况
package KNN;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.LinkedHashSet;
import java.util.List;
import java.util.Set;
import java.util.StringTokenizer;
import java.net.URL;
import java.net.URI;
import java.io.InputStream;
import java.io.InputStreamReader;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.filecache.DistributedCache;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.BufferedReader;
public class KNN {
public static class TokenizerMapper
extends Mapper<Object, Text, IntWritable, Text>{
double dis;
private ArrayList<ArrayList<Double>> test = new ArrayList<>();
static{URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());}
@Override
protected void setup(Context context)throws IOException,InterruptedException{
InputStream in = new URL("hdfs://localhost:9000/data/iris_test_data.csv").openStream();
BufferedReader sb = new BufferedReader(new InputStreamReader(in));
//store the test data
String line;
while ((line = sb.readLine()) != null) {
StringTokenizer itr = new StringTokenizer(line.toString());
while(itr.hasMoreTokens()){
String tmp[] = itr.nextToken().split(",");
ArrayList data = new ArrayList();
for(int i=0;i<4;++i){
//string invert to double
data.add(Double.parseDouble(tmp[i]));
}
test.add(data);
}
}
sb.close();
}
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
//store the train data
String tmp[] = itr.nextToken().split(",");
String label = tmp[4];
ArrayList data = new ArrayList();
for(int i=0;i<4;++i){
data.add(Double.parseDouble(tmp[i]));
}
for(int i=0;i<test.size();i++){
ArrayList tmp2 = (ArrayList) test.get(i);
double dis = 0;
for(int j=0;j<4;++j){
dis += Math.pow(((double)data.get(j)-(double)tmp2.get(j)), 2);
}
dis = Math.sqrt(dis);
String out = label + "," + dis;
context.write(new IntWritable(i),new Text(out));
}
}
}
}
public static class IntSumReducer
extends Reducer<IntWritable,Text,IntWritable,Text> {
private IntWritable result = new IntWritable();
protected static List<String> labels = new ArrayList<>();
int k;
//store the test label
//static{URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());}
@Override
protected void setup(Context context)throws IOException,InterruptedException{
InputStream in = new URL("hdfs://localhost:9000/data/iris_test_label.csv").openStream();
BufferedReader sb = new BufferedReader(new InputStreamReader(in));
String line;
while ((line = sb.readLine()) != null) {
// 假设每行只有一个停用词
labels.add(line.trim());
}
sb.close();
Configuration conf = context.getConfiguration();
k=conf.getInt("k",4);
}
public void reduce(IntWritable key, Iterable<Text> values,
Context context
) throws IOException, InterruptedException {
ArrayList<String> tmp = new ArrayList<String>();
for(Text val: values){
tmp.add(val.toString());
}
System.out.println(tmp);
Collections.sort(tmp,new Comparator<String>(){
public int compare(String s1,String s2){
double d1 = Double.parseDouble(s1.split(",")[1]);
double d2 = Double.parseDouble(s2.split(",")[1]);
return Double.compare(d1,d2);
}
});
ArrayList<String> tmp2 = new ArrayList<String>();
for(int i=0;i<k;++i){
tmp2.add(tmp.get(i).split(",")[0]);
}
Set<String> set = new LinkedHashSet<>();
set.addAll(tmp2);
List<String> labelset = new ArrayList<>(set);
int[] count = new int[labelset.size()];
// initial
for (int i=0;i<count.length;i++){
count[i] = 0;
}
for(int i=0;i<labelset.size();i++){
for (int j=0;j<tmp2.size();j++){
if (labelset.get(i).equals(tmp2.get(j))){
count[i] += 1;
}
}
}
int max = 0;
for(int i=0;i<count.length;i++){
if(count[i] > count[max]){
max = i;
}
}
context.write(key, new Text("pre_label:" + labelset.get(max) + "\t" + "real_label:" + String.valueOf(labels.get(key.get()))));
}
}
public static class KNNCombiner extends Reducer<IntWritable, Text, IntWritable, Text> {
private int k;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
k = conf.getInt("k", 4);
}
@Override
public void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
ArrayList<String> tmp = new ArrayList<>();
for (Text val : values) {
String valueStr = val.toString();
// 检查字符串是否包含逗号
if (valueStr.contains(",")) {
tmp.add(valueStr);
}
}
if (tmp.size() < k) {
for (String val : tmp) {
context.write(key, new Text(val));
}
} else {
Collections.sort(tmp, new Comparator<String>() {
public int compare(String s1, String s2) {
double d1 = Double.parseDouble(s1.split(",")[1]);
double d2 = Double.parseDouble(s2.split(",")[1]);
return Double.compare(d1, d2);
}
});
for (int i = 0; i < k; ++i) {
String out = tmp.get(i);
context.write(key, new Text(out));
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "KNN Classify");
job.setJarByClass(KNN.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(KNNCombiner.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
//job.addCacheFile(new URI("iris_test_data.csv"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
测试集较大情况
package KNN;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.LinkedHashSet;
import java.util.List;
import java.util.Set;
import java.util.StringTokenizer;
import java.net.URL;
import java.net.URI;
import java.io.InputStream;
import java.io.InputStreamReader;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.filecache.DistributedCache;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.BufferedReader;
public class KNN2 {
public static class TokenizerMapper
extends Mapper<LongWritable, Text, LongWritable, Text>{
double dis;
private ArrayList<ArrayList<Double>> train = new ArrayList<>();
private int count = 0;
private int k = 0;
private ArrayList labels = new ArrayList<>();
static{URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());}
@Override
protected void setup(Context context)throws IOException,InterruptedException{
InputStream in = new URL("hdfs://localhost:9000/data/iris_train.csv").openStream();
BufferedReader sb = new BufferedReader(new InputStreamReader(in));
//store the test data
String line;
while ((line = sb.readLine()) != null) {
StringTokenizer itr = new StringTokenizer(line.toString());
while(itr.hasMoreTokens()){
String tmp[] = itr.nextToken().split(",");
ArrayList data = new ArrayList();
for(int i=0;i<4;++i){
//string invert to double
data.add(Double.parseDouble(tmp[i]));
}
labels.add(tmp[4]);
train.add(data);
}
}
sb.close();
}
public void map(LongWritable key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
String tmp[] = itr.nextToken().split(",");
ArrayList data = new ArrayList();
for(int i=0;i<4;++i){
data.add(Double.parseDouble(tmp[i]));
}
for(int i=0;i<train.size();i++){
ArrayList tmp2 = (ArrayList) train.get(i);
//String tmp2[] = itr.nextToken().split(",");
String label = (String) labels.get(i);
double dis = 0;
for(int j=0;j<4;++j){
dis += Math.pow(((double)data.get(j)-(double)tmp2.get(j)), 2);
}
dis = Math.sqrt(dis);
String out = label + "," + dis;
context.write(key,new Text(out));
}
}
}
}
public static class IntSumReducer
extends Reducer<LongWritable,Text,LongWritable,Text> {
private IntWritable result = new IntWritable();
protected static List<String> labels = new ArrayList<>();
int k;
//store the test label
//static{URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());}
@Override
protected void setup(Context context)throws IOException,InterruptedException{
InputStream in = new URL("hdfs://localhost:9000/data/iris_test_label.csv").openStream();
BufferedReader sb = new BufferedReader(new InputStreamReader(in));
String line;
while ((line = sb.readLine()) != null) {
// 假设每行只有一个停用词
labels.add(line.trim());
}
sb.close();
Configuration conf = context.getConfiguration();
k=conf.getInt("k",4);
}
public void reduce(LongWritable key, Iterable<Text> values,
Context context
) throws IOException, InterruptedException {
ArrayList<String> tmp = new ArrayList<String>();
for(Text val: values){
tmp.add(val.toString());
}
System.out.println(key.toString()+tmp);
Collections.sort(tmp,new Comparator<String>(){
public int compare(String s1,String s2){
double d1 = Double.parseDouble(s1.split(",")[1]);
double d2 = Double.parseDouble(s2.split(",")[1]);
return Double.compare(d1,d2);
}
});
ArrayList<String> tmp2 = new ArrayList<String>();
for(int i=0;i<k;++i){
tmp2.add(tmp.get(i).split(",")[0]);
}
Set<String> set = new LinkedHashSet<>();
set.addAll(tmp2);
List<String> labelset = new ArrayList<>(set);
int[] count = new int[labelset.size()];
// initial
for (int i=0;i<count.length;i++){
count[i] = 0;
}
for(int i=0;i<labelset.size();i++){
for (int j=0;j<tmp2.size();j++){
if (labelset.get(i).equals(tmp2.get(j))){
count[i] += 1;
}
}
}
int max = 0;
for(int i=0;i<count.length;i++){
if(count[i] > count[max]){
max = i;
}
}
int index = (int) key.get();
index/=16;
if (index < labels.size()) {
context.write(key, new Text("pre_label:" + labelset.get(max) + "\t" + "real_label:" + String.valueOf(labels.get(index))));
} else {
context.write(key, new Text("pre_label:" + labelset.get(max) + "\t" + "real_label: unknown"));
}
//context.write(key, new Text("pre_label:" + labelset.get(max) + "\t" + "real_label:" + String.valueOf(labels.get((int) key.get()))));
}
}
public static class KNNCombiner extends Reducer<LongWritable, Text, LongWritable, Text> {
private int k;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
k = conf.getInt("k", 4);
}
@Override
public void reduce(LongWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
ArrayList<String> tmp = new ArrayList<>();
for (Text val : values) {
String valueStr = val.toString();
// 检查字符串是否包含逗号
if (valueStr.contains(",")) {
tmp.add(valueStr);
}
}
if (tmp.size() < k) {
for (String val : tmp) {
context.write(key, new Text(val));
}
} else {
Collections.sort(tmp, new Comparator<String>() {
public int compare(String s1, String s2) {
double d1 = Double.parseDouble(s1.split(",")[1]);
double d2 = Double.parseDouble(s2.split(",")[1]);
return Double.compare(d1, d2);
}
});
for (int i = 0; i < k; ++i) {
String out = tmp.get(i);
context.write(key, new Text(out));
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "KNN Classify");
job.setJarByClass(KNN2.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(KNNCombiner.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
//job.addCacheFile(new URI("iris_test_data.csv"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Comments | NOTHING